26 results found

The smartphone market in Q2 2026 hit historic lows due to a memory shortage, but Apple and Samsung are thriving. Consumers face higher prices, especially for budget phones, but benefit from longer software support, encouraging extended device ownership.

Quick Verdict MSI has delivered a significant boost to AMD AM5 users, with new beta BIOS updates validating China-made CXMT DDR5 memory at previously unattainable speeds. Dual-DIMM configurations can now hit an

Verdict Polymatt's DIY USB drive featuring hand-threaded magnetic core memory is a fascinating, meticulously crafted homage to computing's past. While utterly impractical for modern storage needs with its 64-bit

Bloom filters are probabilistic data structures that efficiently determine if an item is "definitely not" or "possibly" in a set, using minimal memory. They are ideal for scenarios requiring fast membership checks on vast datasets where a small rate of false positives is acceptable. This article details how to build one from scratch in Python, covering its core components, hash function design, and how to size it for a target error rate.

Micron Technology has become a Wall Street favorite, with its valuation soaring amidst booming demand for AI memory chips, particularly High-Bandwidth Memory (HBM). Its stock surged over 236% in a month, briefly surpassing Meta and Tesla's market cap, driven by blockbuster earnings and strategic long-term agreements to mitigate market volatility.

Apple is actively lobbying the US government for formal approval to acquire memory chips from ChangXin Memory Technologies (CXMT), China's foremost DRAM manufacturer, which is currently on the Pentagon's military-linked
This article explores the reverse engineering of IBM's MCGA gate arrays, the 72X8300 Memory Controller and 72X8205 Video Formatter. It details newly discovered, previously undocumented features like genlock capabilities, various clock controls, and manufacturing test registers. These insights offer significant value for hardware enthusiasts, preservationists, and emulator developers seeking a deeper understanding of vintage IBM PC graphics hardware.
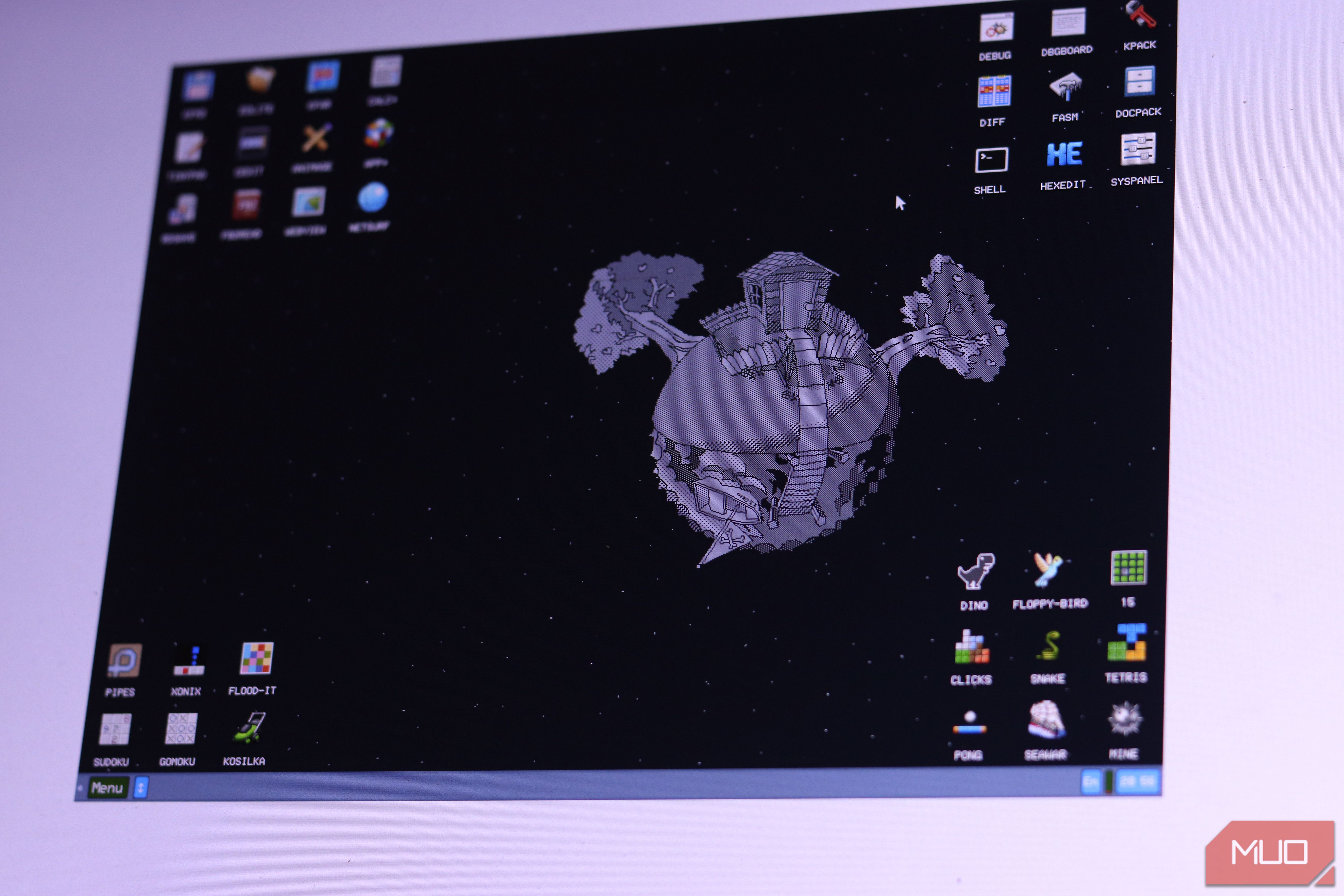
Welcome to a guide on KolibriOS, an incredibly small yet powerful operating system that challenges the notion of modern software bloat. In an era where operating systems demand gigabytes of storage and memory, KolibriOS
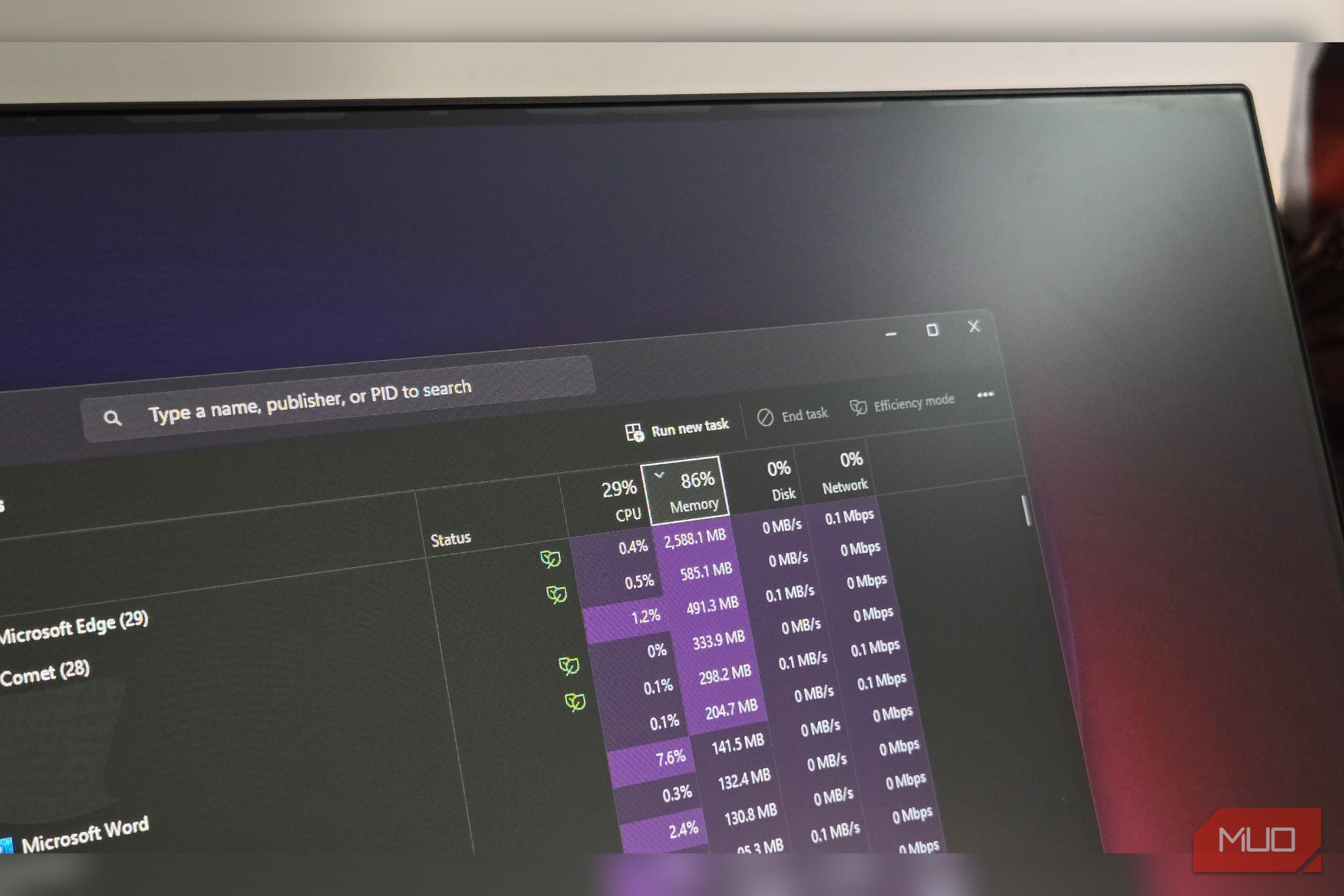
Discover why turning off Windows Prefetch can degrade performance, understand how Windows manages memory efficiently, and learn to correctly interpret your PC's RAM usage in Task Manager.

Apple has introduced a groundbreaking architecture at WWDC26 for on-device AI, overcoming the long-standing DRAM memory limit. Its new AFM 3 Core Advanced model stores 20 billion parameters in NAND flash, using a unique Instruction-Following Pruning (IFP) method to dynamically load expert modules into DRAM. This innovation significantly boosts local AI capabilities for agentic workloads.

Verdict: A Powerful Upgrade with Troubling Implications ChatGPT's latest memory upgrade, dubbed Dreaming V3, represents a significant technical leap for OpenAI's chatbot, promising more personalized and context-aware

The Pelsee P1 Pro 4K Front and Rear Dashcam Bundle is currently an unbeatable deal on Amazon, dropping to just $49.99 with a special coupon code. This bundle offers a high-resolution 4K front camera with a premium Sony STARVIS 2 sensor for superior low-light recording, a 1080p rear camera, and includes all necessary accessories like a 64GB memory card. It's a fantastic value for enhanced road safety and recording.

Quick Verdict Origin Code's 256GB (2x128GB) DDR5-8000 CUDIMM memory kits mark a monumental shift, bringing previously enterprise-exclusive quad-rank memory to the mainstream. With unheard-of capacities and impressive
This article explores how a 10-year-old Intel Xeon E5-2620 v4 server with 128 GB DDR3 RAM and no GPU can run a modern LLM like Gemma 4 26B-A4B at reading speed. It highlights that LLM inference is often memory-bound and showcases deep optimization techniques using `ik_llama.cpp`, including speculative decoding, CPU-aware MoE routing, advanced memory management, and specialized attention kernels. The success demonstrates that granular software control can unlock significant performance on older, abundant-RAM hardware.

AI's explosive demand for high-bandwidth memory (HBM) is causing an unprecedented reallocation of DRAM production from consumer devices to data centers, leading to massive price surges for smartphone memory. This crisis is pushing affordable smartphones out of reach for millions, particularly in developing nations, and impacting premium brands as memory makers prioritize highly profitable AI chips.
Δ-Mem is a lightweight memory mechanism that augments frozen LLM backbones with a compact online state. It uses a fixed-size state matrix, updated by delta-rule learning, to generate low-rank corrections for attention computation during generation. This approach significantly improves performance on memory-heavy tasks without costly context expansion or full model fine-tuning.

OpenAI has updated ChatGPT to the GPT-5.5 Instant model, introducing a new partial memory feature that shows some of the context influencing AI responses. While improving transparency and accuracy, this incomplete observability layer could challenge enterprises by creating competing context logs alongside existing audit systems. Businesses must now formalize memory management to reconcile these new insights with their established processes.

As AI models continue their exponential growth, memory capacity, bandwidth, and latency consistently present the most formidable challenges for hardware engineers. The need for larger models often forces developers into

Google is in talks with Marvell Technology to develop two custom AI inference chips, including a memory processing unit and an inference-optimized TPU. This move signals Google's strategic diversification of its chip supply chain, expanding beyond its primary partner Broadcom to address the rapidly growing demand and cost of AI inference workloads. The collaboration aims to enhance Google's competitive advantage in the burgeoning custom silicon market.

Retro Rewind: Video Store Simulator offers a nostalgic journey back to the '90s, re-creating the everyday tasks of managing a local video rental shop. This title joins a growing trend of "work simulators" that have

This article details setting up Ollama with Gemma 4 26B on an Apple Silicon Mac mini for an always-ready local LLM environment. It covers installation, model pulling, and advanced configurations like auto-starting Ollama, preloading the model using `launchd` agents, and keeping models loaded indefinitely with `OLLAMA_KEEP_ALIVE` to leverage fast inference on Apple Silicon. Practical takeaways emphasize the benefits for developer workflows and memory management considerations.

Are you ready to take a trip down memory lane and relive the golden age of arcade gaming? The My Arcade Atari Gamestation Go offers a fantastic opportunity to do just that, bringing 200 classic titles right to your

Recent missile strikes and escalating global tensions have revealed how millions fall into "doomscrolling," the compulsive consumption of bad news through endless digital updates. This behavior, driven by our evolutionary wiring to prioritize threats and platforms engineered for engagement, can quickly spiral from seeking information into a detrimental feedback loop. Cognitive scientists highlight that human memory is biased towards danger, making negative news hard to ignore, while studies link doomscrolling to increased anxiety, depression, and even trauma-like responses, impacting mental well-being.

David Gewirtz's ZDNET article outlines 7 AI coding techniques for shipping reliable products fast. The framework emphasizes structured interaction over simple prompts, treating AI as a disciplined developer. It details methods for persistent memory, audit trails, and sequential processing to boost speed and quality.
SplatHash offers a novel approach to image placeholders, encoding any image into a fixed 16-byte string (22-char base64url). It stands out with significantly faster decoding and lower memory allocations compared to alternatives like BlurHash and ThumbHash, making it ideal for performance-critical UIs where client-side rendering speed is paramount. It uses Oklab color space and Gaussian blobs packed into 128 bits.
